Introducing Simple Moderation: Real-time moderation for LLM- and user-generated content
We're using AIs and machine learning classifiers to moderate content before passing that on to human beings.

I had a great time at the University of San Diego last week at The International Society for Research on Internet Interventions (ISRII) 2025 annual conference. A good number of clients and collaborators were there demonstrating everything from cancer medication adherence apps to mental health chat bots.
Earlier in the year, I decided to use the conference as an excuse to build something that I felt was needed, but no-one was asking for quite yet: moderation infrastructure for real-time conversational systems that are starting to incorporate large language models and user-generated content into interactions with vulnerable research and treatment populations.
A typical scenario looks like this: a mental health study may take an existing intervention from a field like cognitive behavioral therapy (CBT) and transform what was initially designed as an in-person interaction and transform it into an online experience delivered via a messaging channel like WhatsApp or SMS. For example, if one were building a cognitive restructuring bot, you might start out with a worksheet and begin translating its instruction into a chat bot algorithm.

We've been building systems like this for years with Django Dialog Engine, which allows us to create branching text-based conversations (dialogs) that can be scheduled ahead of time or on-demand. For example in the worksheet above, Step 2 encourages patients to choose one of four broad classes of feelings to focus on for a single cognitive restructuring exercise. In our software system, we'd translate that into a branching prompt that leads to an interaction crafted to the response provided.
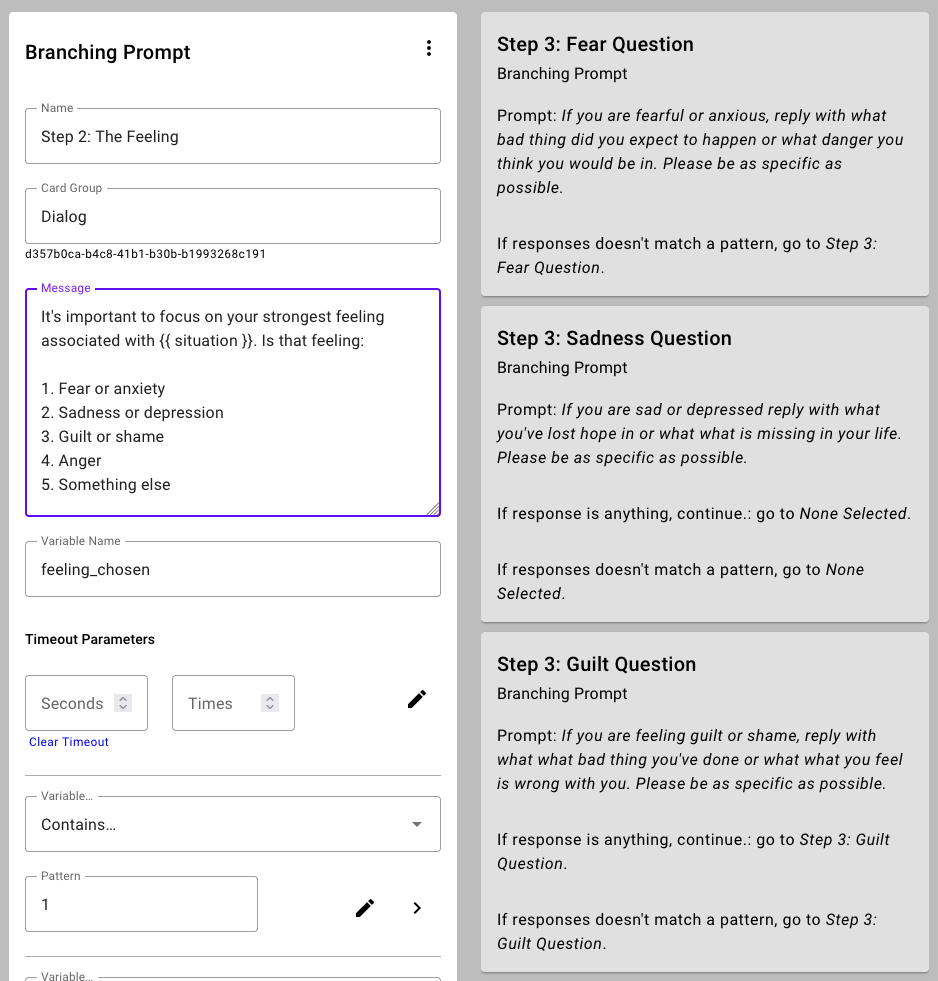
Up until the past year or so, we've used this approach for reaching thousands of patients and research participants through programs like Small Steps. Researchers would take existing evidence-backed approaches from offline contexts (such as talk therapy) and translate them into these dialogs that can be automatically administered, eliminating having available human staff as a limiting factor.
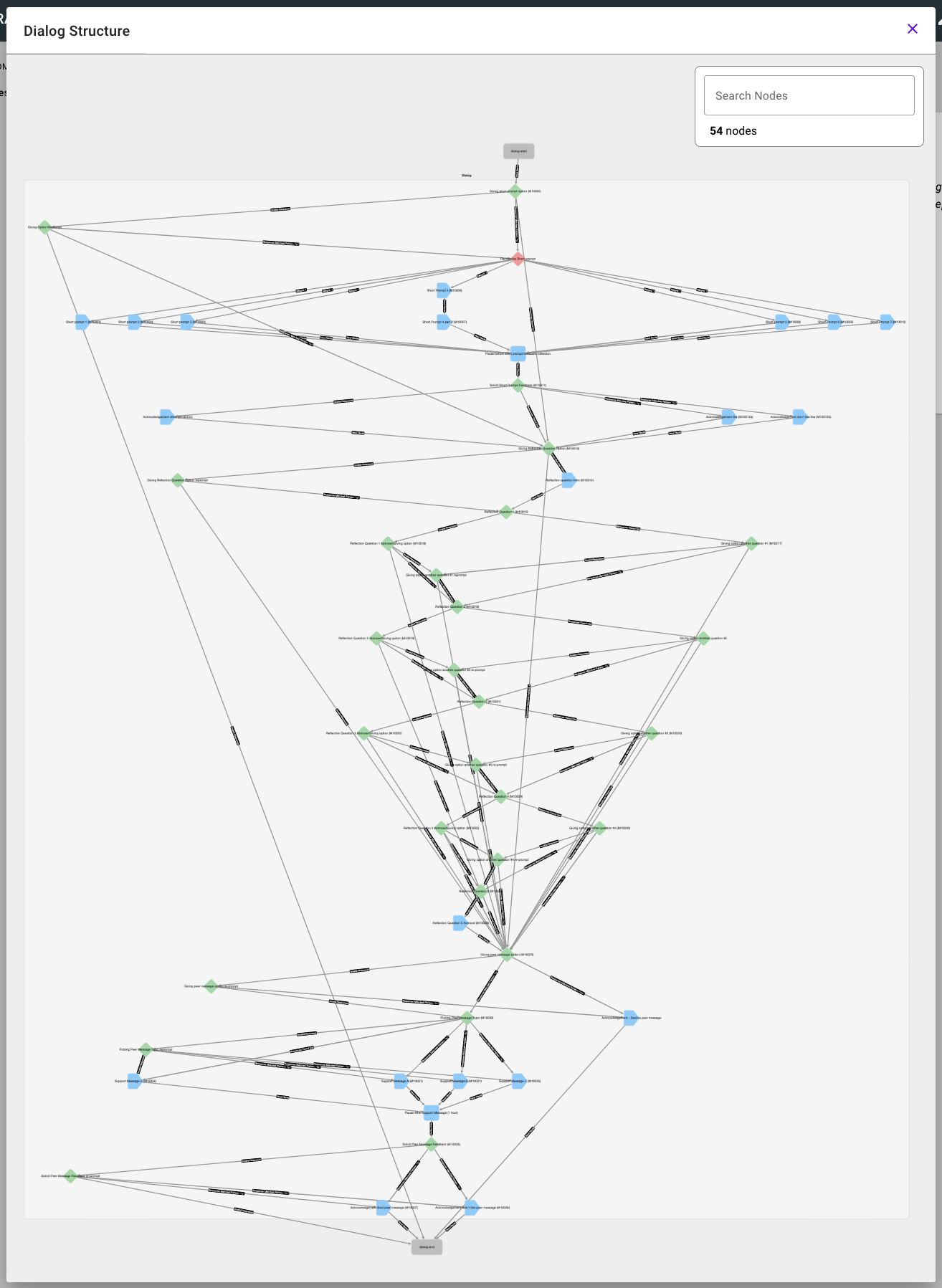
From my conversations with researchers, patients and study participants initially enjoy this mode of interaction, as it feels more like they're interacting with someone, instead of filling out a worksheet that feels like homework. However, that satisfaction begins to wear off after repeated interactions with these rule-based systems, and they begin to feel more like the dreaded worksheets again, as users exhaust all the pre-programmed pathways and start to traverse the same pathways with the same responses repeatedly.
Generative AI and large language models - as well as user-generated content -provide options for maintaining long-term adherence and engagement with these tools.
If you're working with a patient group or study population who share the same situation, one way to spur engagement is to encourage users to write content themselves as part of the intervention. For example, if you're working with a group for whom strict medication adherence is important (such as in chemotherapy), when users are doing well, you may prompt them to write encouraging notes intended for their future selves when they might not be doing as well as they are today. You may implement a strategy where participants write messages to be shared with other participants, reminding them that they aren't tackling the same problem alone, and that there are others succeeding and struggling alongside them. A system like Django Dialog Engine can collect and "bank" these messages for use later on.
In a similar fashion, a generative AI model like an LLM might be thought of as a bottomless bank of messages, given the right prompts.
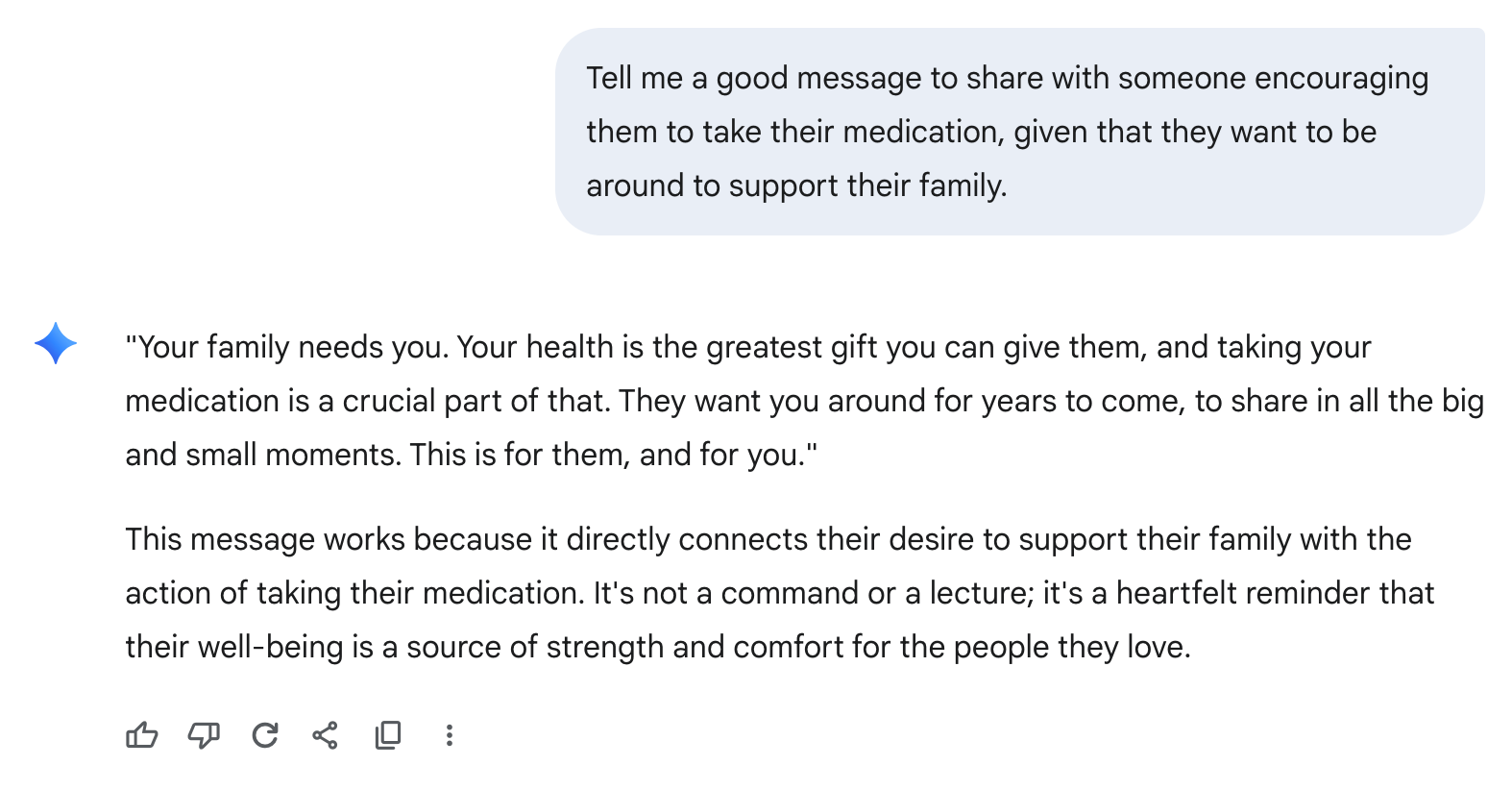
This technique becomes potentially much more useful and personalized, if we can pass additional context about the recipient to the model.
That all sounds great, right? Well, let's remember our Robert Heinlein and his saying, "There's no such thing as a free lunch." LLMs can be very powerful, but there are a number of things that we must always keep in mind:
- Unless you are running the model directly yourself, your data and intervention are in the hands of a third party that may have incentives that run counter to your own and your users'.
- LLMs are probabilistic and do not deterministically repeat the same responses, even to the exact same prompt.
- You did not select the data that was used to train the LLMs, and it can generate malicious responses to benign queries.
- You often do not have full control over the parameters that a model is running under. For example, if the model's owner has the "temperature" turned too high, the model may begin exhibiting erratic behavior, which may be the last thing you want to present to a user with a sensitive mental health condition.
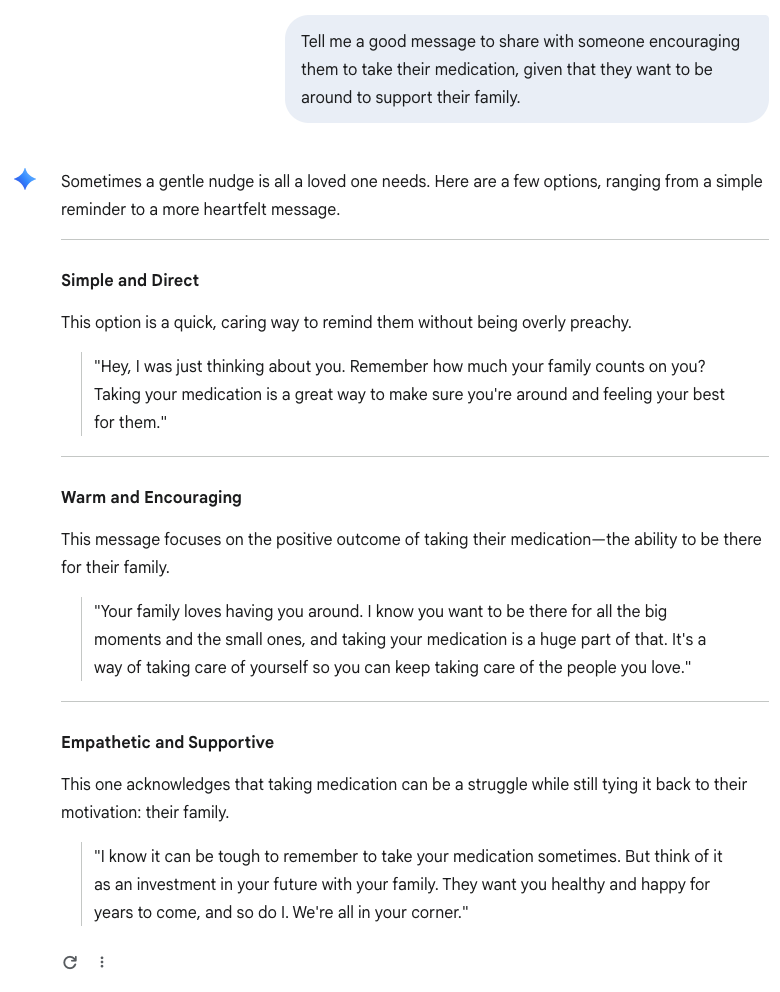
Unlike the rule-based system presented earlier - where deterministic activity generates deterministic responses - LLMs function with a degree of randomness and unpredictability, leading to some researchers highlighting the dangers of stochastic parrots.
So, with the promise of LLMs in mind, balanced with the potential risks that they may introduce, we figured that we could use this as an opportunity to build some new infrastructure for researchers to help them leverage LLM technology in a safe and responsible manner, using content moderation as our frame.
Our idea is pretty simple - we would like to use LLMs to generate content in the middle of real-time dialogs, but we would like to include some guardrails to help avoid sending inappropriate content to users or study participants. We'd like the speed of of the automated systems to keep the conversations moving briskly, but we would like the human judgement to keep the conversations safe.
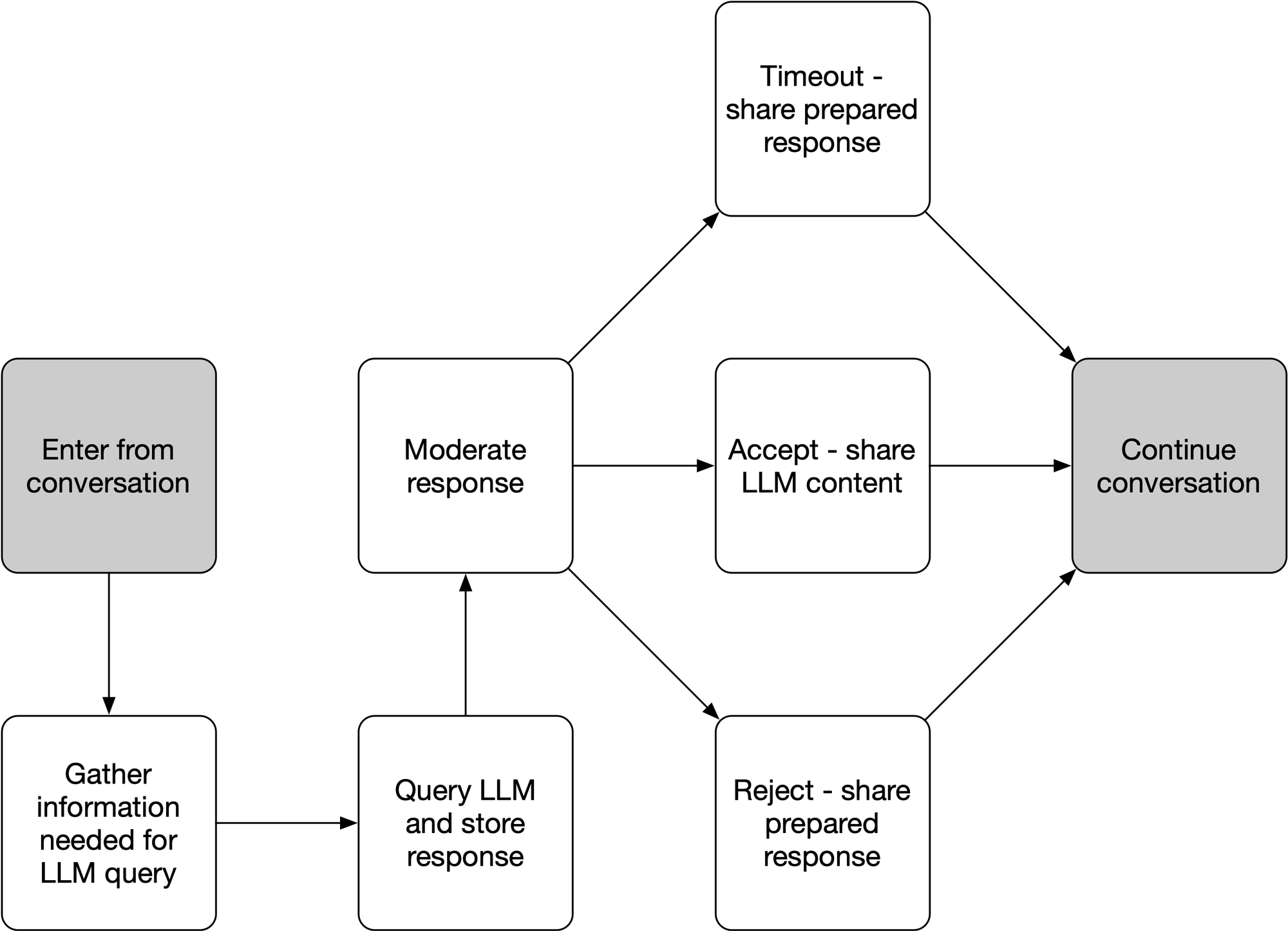
Borrowing a technique from machine learning - boosting - we created an ensemble of automated agents that evaluate any newly-generated content and vote whether to use the content or reject it. We use configurable vote percentage thresholds to determine what we will automatically accept and what we will reject, with any content falling between those thresholds (the "realm of uncertainty) sent to a human to manually moderate.
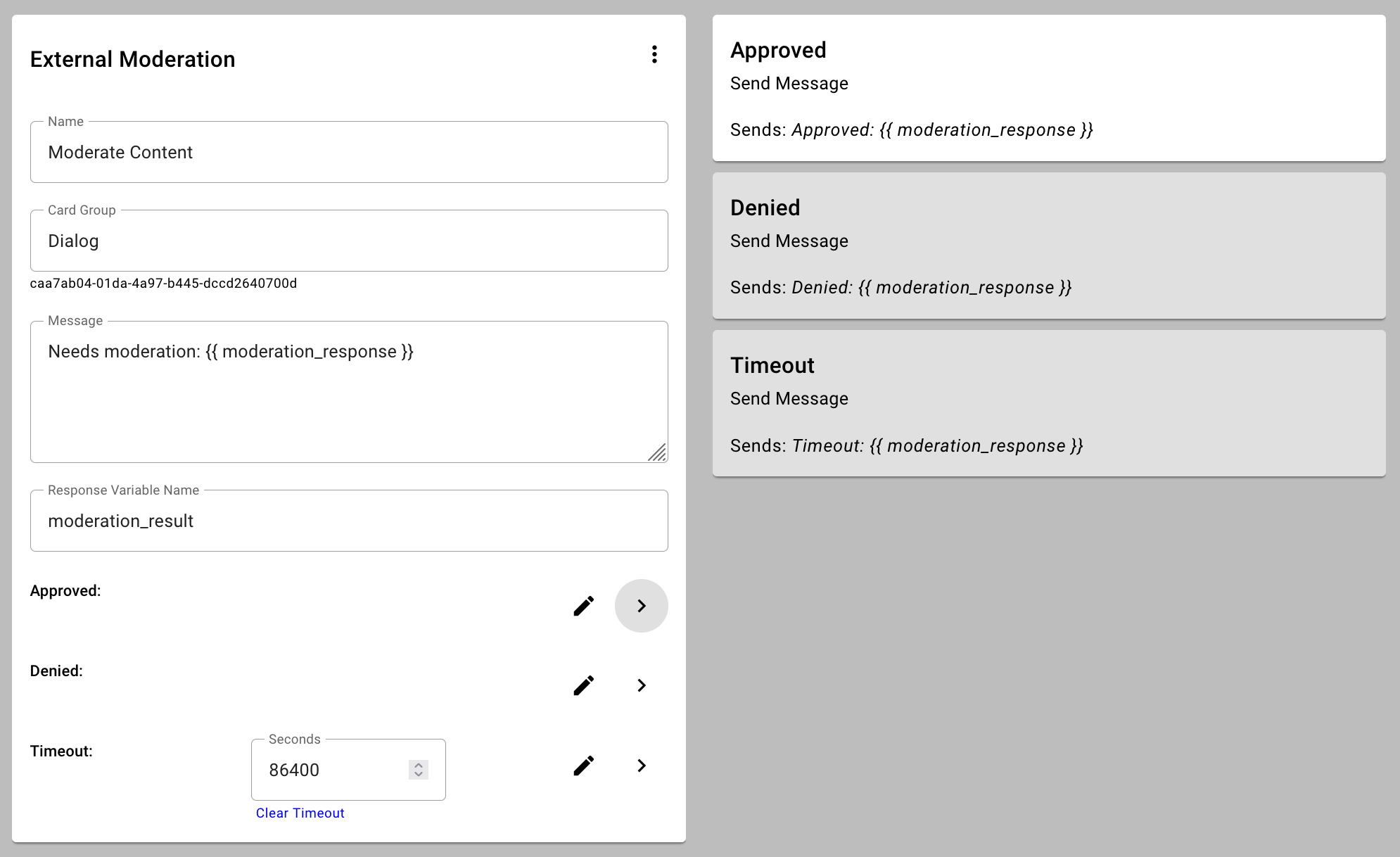
For example, if we have five agents voting and our automatic reject threshold is set to be 0.35 and our automatic accept threshold is set to be 0.75, any content that two or more agents find objectionable will be rejected automatically (0.40 > 0.35). Any content that was not rejected and four or more agents finds acceptable would be accepted automatically (0.80 > 0.75). And for any content falling between those thresholds - in this case, if we have some agents not voting - we fall back to human moderators that we contact with a moderation link via SMS or e-mail. (The system also includes a timeout parameter where a backup choice can be made if a human is not available in time.)
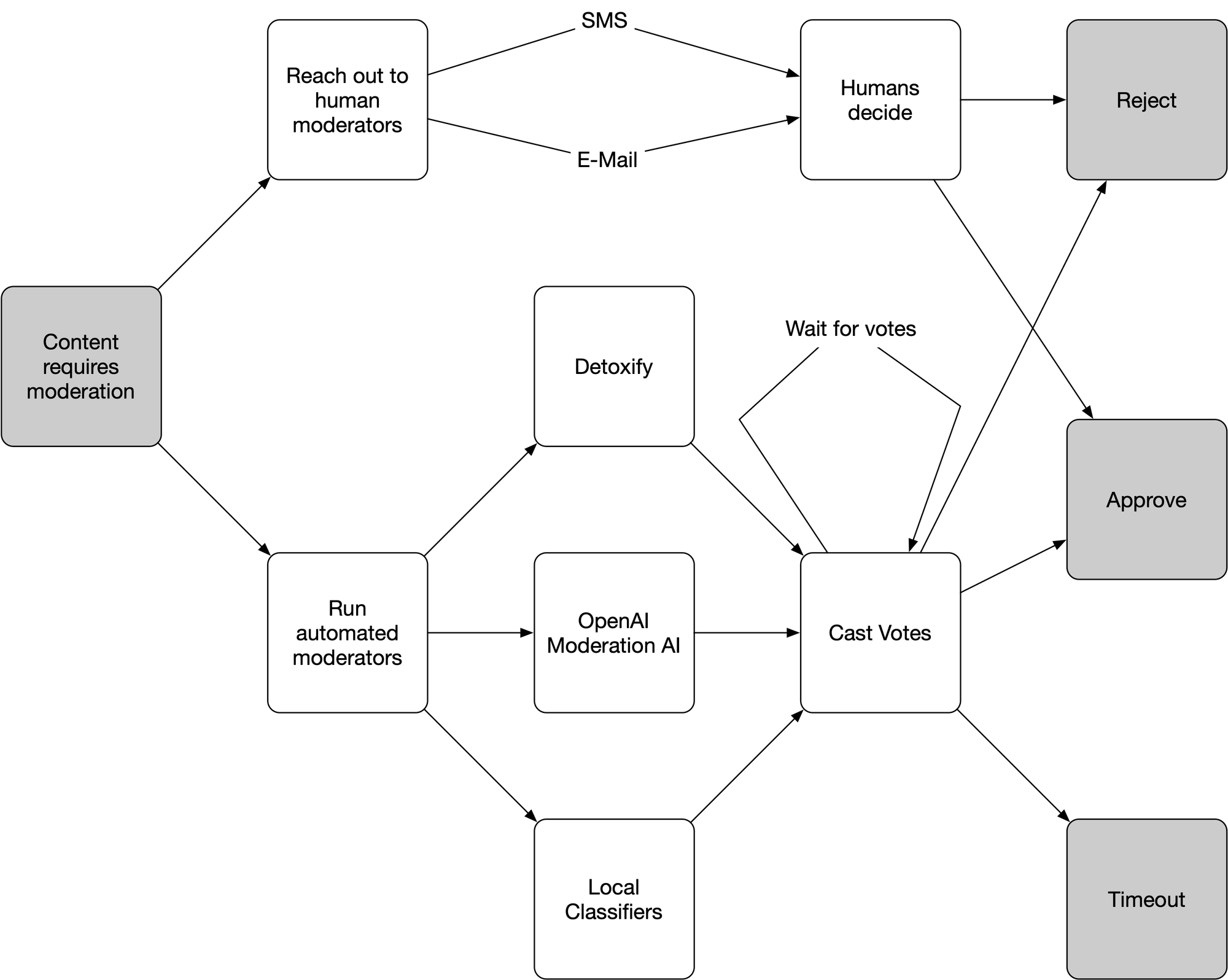
Note that in the current implementation, one human vote to accept or reject overrides the all of the votes of the automated moderators. This can be changed in contexts where human moderators are always available (such as in a call center context) or you don't have complete confidence in all the human moderators (e.g. you've hired a new third-party to be responsible for this).
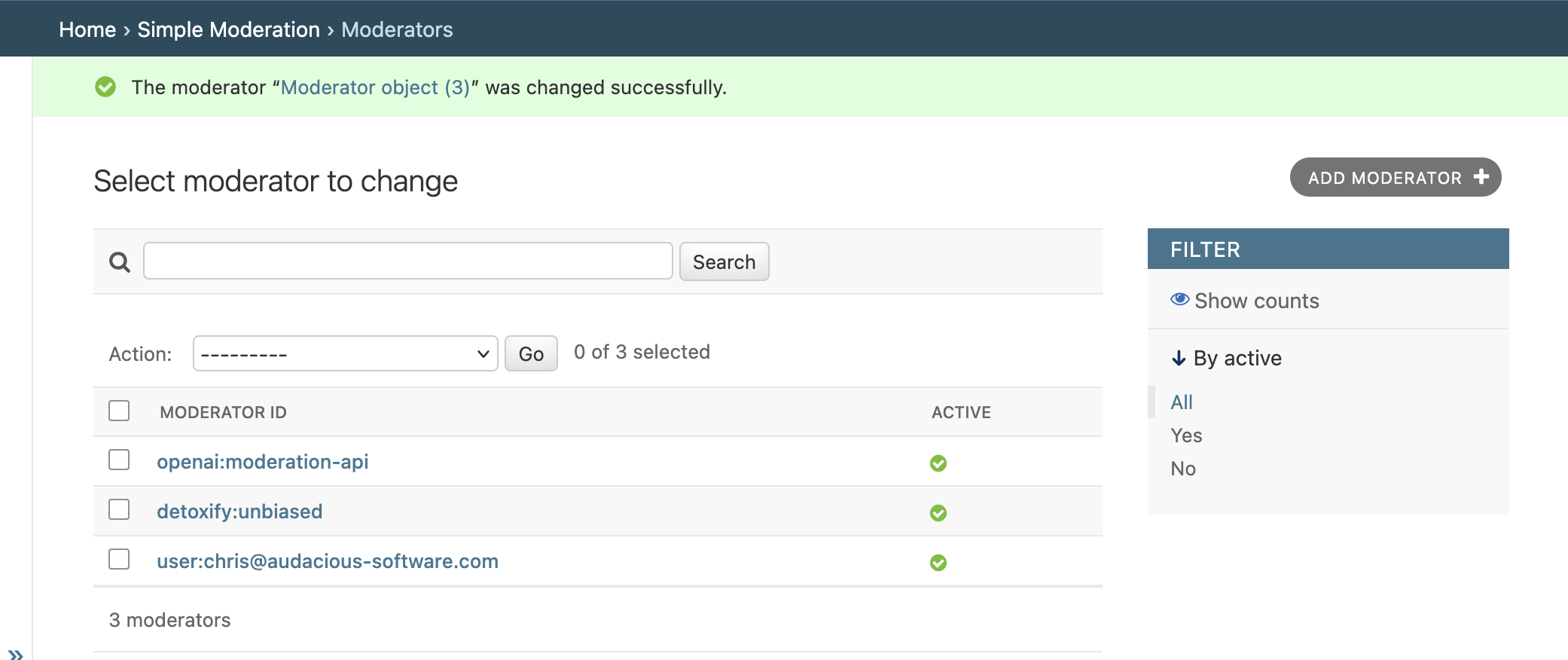
On the backend, moderators can be managed from the Django administration interface. In the example below, we have three moderators:
- One human (chris@audacious-software.com)
- One automated moderator using Unitary AI's Detoxify unbiased classifier.
- One automated moderator using OpenAI's moderation API.
The human moderation infrastructure and Detoxify classifiers are included with the Simple Moderation package while the OpenAI moderator is included with the Simple Generative AI package, and imported into the system using a standard extension mechanism: create a file called moderation_api.py in a Django app and implement the moderate function within.
Our first example is in the Simple Generative AI package:

This implements a simple routine that passes the moderation request's message (request.message) to the OpenAI client library. That library (through a remote API call), inspects the content and renders a decision through a "flagged" property about whether the content is acceptable or not.
While OpenAI provides a convenient moderation feature in their APIs, we're also building wrappers around other LLMs that allow them to function as moderators themselves. We are also incorporating existing third-party moderation systems, such as Hive Moderation. Finally, this simple design also empowers developers to build their own basic moderation agents. For example, if you're working in a context where particular keywords are prohibited, a moderator that votes deny if any of those keywords are present (and abstains otherwise) is just a few lines of Python code and a block list.
While this represents our initial work in this space, we expect to expand upon it significantly upon it in the months and years ahead. Our first efforts will be expanding the pool of available automated moderators and fine-tuning the human moderator experience.
Right now, moderation requests are sent to everyone at the same time, and humans can log in to moderate and discover that the automated voters already reached a decision threshold. This can be improved by waiting to actually reach out to human moderators until after all the automated agents have had a chance to vote.
Related to this is a moderation review function - at the end of the day, it may be useful bring in a human reviewer to inspect the decisions made by the automated voters and tag the overall decision as correct or not. This allows us to begin weighting the votes of the various agents. Agents that cast votes that agree with the human reviewer will have their vote weights increased. Agents that do not agree with human reviewers see a decreased vote weight. As time goes on, the local system ends up trained to better match the context in which it is deployed.
This kind of work is the type of project that we founded BRIC to pursue. We're far too early in the technology experimentation lifecycle for any of our clients to explicitly request moderation as a feature, but we've seen enough history to know that this will grow in importance as LLMs become more integrated into our lives and research. I'm not going to claim that this will be the ultimate instantiation of a system like this, but it gives us a good foundation to work from, where we can confidently support researchers' growing demands to use LLMs and generative AIs in their projects, while also not neglecting the safety and security of users and research participants who may use the systems we build.
I like to say that our job is to make it simple and easy for researchers to do the responsible things in building their research system, and this Simple Moderation framework is a great example of that philosophy in action.
The slide deck for our demonstration at ISRII is available here.



